Tiny Recusive Models
Posted on Tue 03 March 2026 in posts
Paper Review
I found this paper a few months ago and wanted to write a brief overview of the work. Below is my understanding of it and some impressions and future directions I think this may go.
Setup
This paper explores how one can improve existing reasoning abilities of the LLMs avoiding common resource constraints associated with LLMs.
Highlighting limitations of modern techniques like Chain-of-Thought reasoning and taking advantage of new Hierarchical reasoning method (HRM), the authors develop an improvement called Tiny Recursive Model (TRM).
Key Idea
The HRM consists of two steps:
- recursive reasoning: data flows through two networks multiple times where each output becomes the new input to the two networks
- deep supervision: supervised learning step with residual connections simulating deep network behavior
Two issues highlighted by the authors of TRM are:
- Potential problems reaching a fixed point on which HRM relies (it may not be reached in practice while guaranteed theoretically)
- A step that relies on a costly reduction of supervision pass via Q-learning
Method Overview
Key finding is that the method simply uses a recursive iteration of one network for multiple steps and then finally feeding the output into another network. The output of that last step is then used for backpropagation through the entire model. In fact, additional investigation showed that one network may be more than enough to improve benchmark performance.
The model takes advantage of exponential moving average and, more interestingly, performs better without relying on attention. This is surprising considering how much impact the transformer module has had on the AI developments.
Architecture / Algorithm
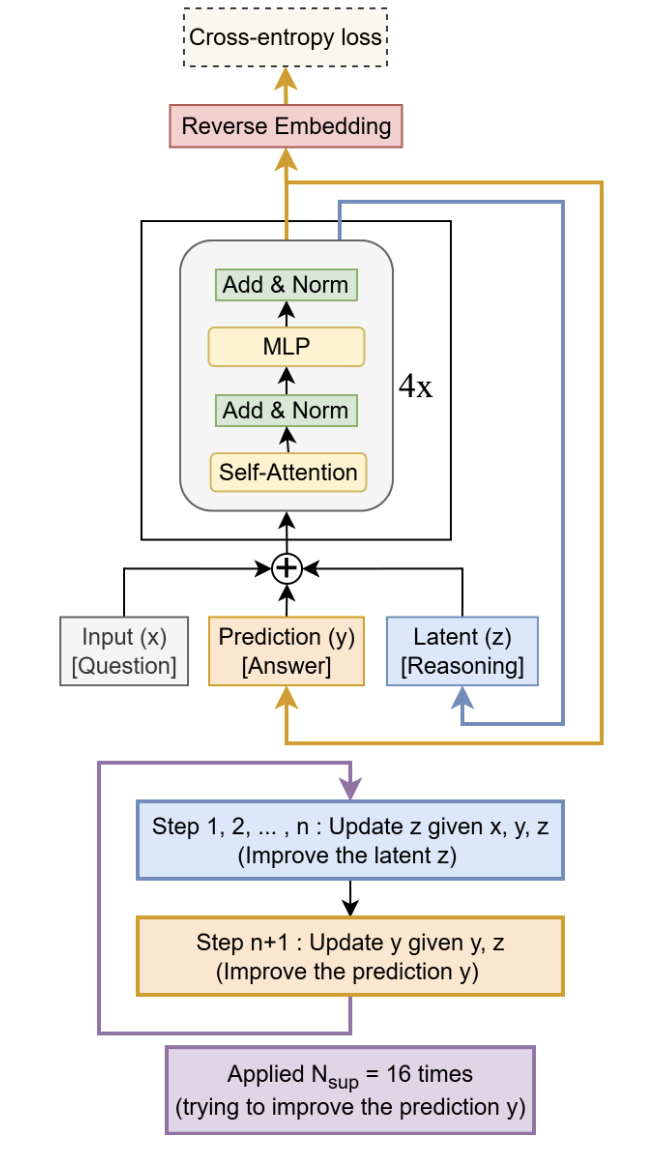
Results
The TRM model outperformed HRM on Sudoku puzzle going up from 55% accuracy to 87.4% on a transformer-free variant.
On ARC-AGI benchmarks, geometric puzzle evaluation datasets for modern generative models, the TRM model with only 7 million parameters and self-attention mechanism reaches over 44% accuracy. For comparison, this outperforms models such as o3-mini-high and Deepseek-R1 on the same benchmark.
Reflections and Why It Works
This is the big question that I think has most fruitful directions for future explorations. As with most modern ML models, architecture decisions lead to most improvement compared to fundamental mathematical explanations. The authors suspect that the key to high performance here lies in the recursion step that may lead to a form of overfitting which encourages generalization.
It's possible that answers lie in the direction of both parameter counts and model size effects combined with recursive computation effects. Iterative computation with skip connections as outlined in the figure, could have effect on retention of informational value of the data by the model.