My Flow Matching Experiments
Posted on Sun 22 March 2026 in posts
Note: For a more elaborate version of this text, see this post where I describe the first step in implementing the library for flow matching.
What is Flow Matching?
Flow matching is a recent generative modeling technique emerging as an alternative to diffusion models. Diffusion models add and remove noise using stochastic differential equations (SDEs), while flow matching relies on the concept of flow - a solution to a deterministic first-order differential equation (ODE) with known initial conditions:
This equation describes a function of time evolving or "flowing" from time 0 to time \(t\). The function \(u(t, x)\) is called a velocity field. Flow matching method is easier to train, requires fewer generation steps and has competitive or better sample quality.
As with any generative model, we would like to be able to generate an object, for instance, an image from a general distribution \(q(x)\) of images. Flow matching gives us a function \(p(t, x)\) that depends on time \(t\) in such a way that, for example, \(p(0, x) \sim \mathcal{N}(0, 1)\) (a standard normal Gaussian) and \(p(1, x)\sim q(x)\). So, as time goes from 0 to 1, our generating distribution "flows" from random Gaussian to target distribution.
The problem: \(q(x)\) is unknown. There is no closed form distribution for any image data and hence we cannot just solve an ODE and sample an image.
The solution: while we do not know the true distribution, we have individual points. We can use individual points (samples of the distribution) to approximate the way our function evolves from known distribution to the unknown.
Example
Let's define a time-dependent path from a random variable \(X_0\) to a given data point \(x_1\):
Since \(X_0\) comes from a known distribution, our original ODE is now solvable: taking a derivative of \(X_t\) gives us the velocity field. Such a velocity field is conditional on our choice of \(x_1\).
Knowing the velocity field, the solution is clear: sample the data \(N\) times, train a neural network to estimate velocity field for each sample. Then at generation time, we simply solve the ODE using the said network as our velocity field and evaluate at time \(t=1\).
tinyflow: A Flow Matching Library
This post describes a library I created for learning about and experimenting with flow matching based on the examples and theory from Flow matching guide and code.
The core of the library relies on tinygrad, a machine learning framework built entirely on Python. It's lightweight and works on any device accelerator (e.g. it seamlessly lets me train models on Apple's MPS framework and on NVIDIA cards with CUDA).
Features
When I set out to build this, I wanted to run experiments as close as possible to what was described in the original Flow Matching guide paper. I implemented base classes for schedulers, interpolation paths, ODE solvers, and later on I added better logging and rudimentary FID support (though incomplete). More on each below.
Interpolation Paths
At any time \(t\), we construct an interpolation between starting point (random variable from known distribution) and a data point. We also construct interpolation of the velocity field at that time moment. Mathematically this looks like
and
The model is trained to predict \(\dot{x}_t\). This example is called an affine path. A more specific example is an optimal transport path
Schedulers
A scheduler is the pair \((\alpha_t, \sigma_t)\) from above. For optimal transport, this pair is \((t, (1-(1-\sigma))\). There are various different examples of schedulers supported by the package:
| Scheduler | \(\alpha_t\) | \(\sigma_t\) |
|---|---|---|
| Linear | \(t\) | \(1 - t\) |
| Polynomial (n) | \(t^n\) | \(1 - t^n\) |
| Cosine | \(\sin(\pi t/2)\) | \(\cos(\pi t/2)\) |
| LinearVarPres | \(t\) | \(\sqrt{1 - t^2}\) |
Solvers
This is a collection of ODE solvers supported by the package:
- Euler
- Midpoint
- RK4
- Heun
- and a DDIM-style deterministic sampler that lets you generate with 10–50 steps instead of 100+.
Training Loop
The package includes an extendable trainer class that I adapted to individual datasets and targets. The training loop for a flow matching problem in general looks as follows:
- Sample \(x_1\) (data), \(x_0\) (noise), random time moment \(t\)
- Compute \(x_t\) and target velocity via the path
- Train the network to predict velocity: \(v_θ(x_t, t) \approx dx_t\)
- Compute MSE loss
Here is a pseudocode example of an epoch iteration, implemented inside a trainer class:
for batch in self.dataloader:
x_batch, _ = batch
x = T(x_batch) # convert to Tensor
t = T.rand(x.shape[0], 1) * 0.99 # avoid boundaries
x_0 = T.randn(*x.shape)
x_t, dx_t = self.path.sample(x_1=x, t=t, x_0=x_0)
out = self.model(x_t, t)
self.optim.zero_grad()
loss = self.loss_fn(out, dx_t)
loss.backward()
optimizer.step()
Path Sampling
A path sampler (path.sample function) returns the result of computing:
x_t = alpha_t * x_1 + sigma_t * x_0
dx_t = alpha_t_dot * x_1 + sigma_t_dot * x_0
Where alpha and sigma are determined by your scheduler.
Examples
Let's see some examples generated via this package. All of this was trained on an M1 MacBook Pro with 16GB of RAM.
MNIST
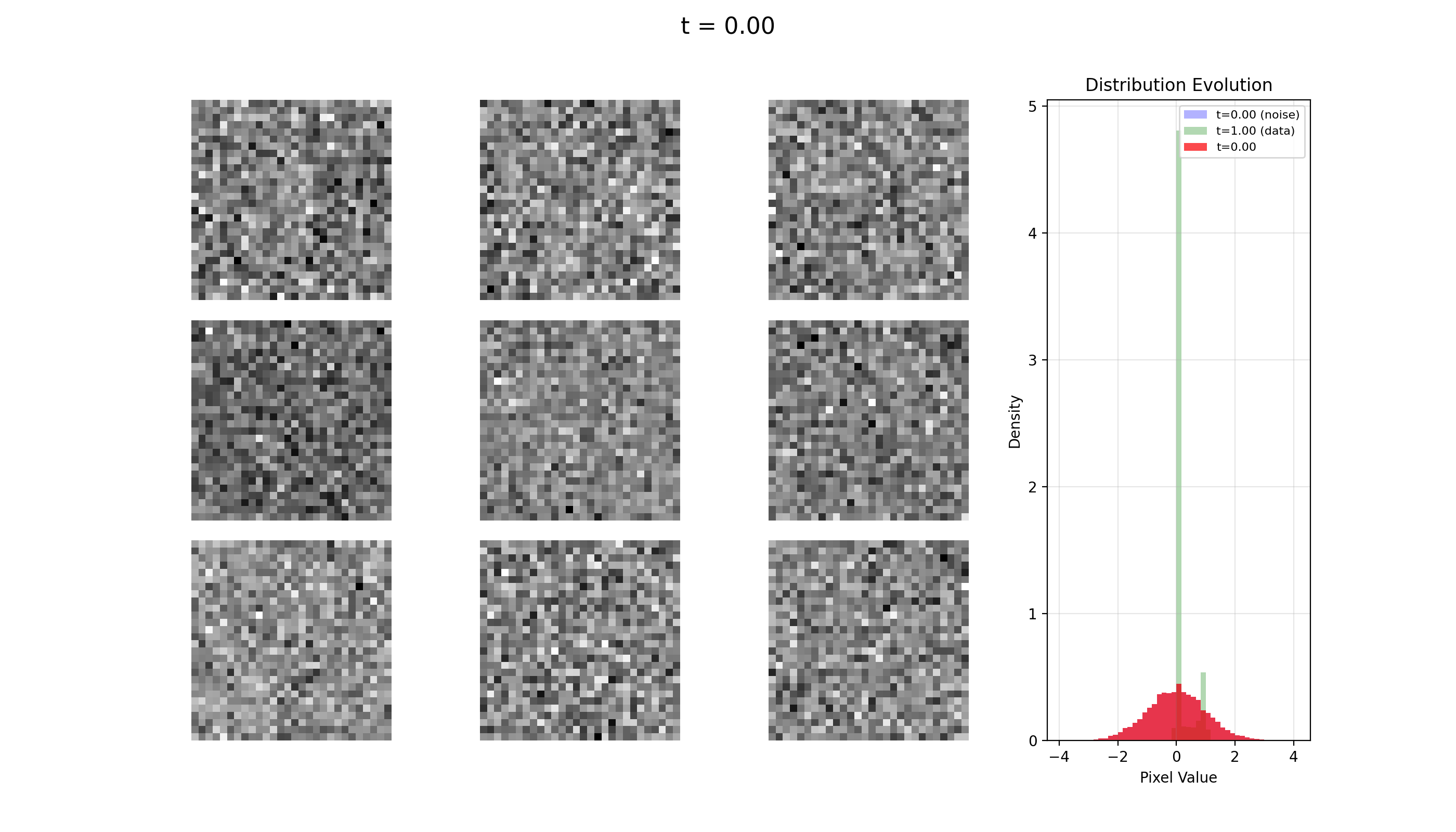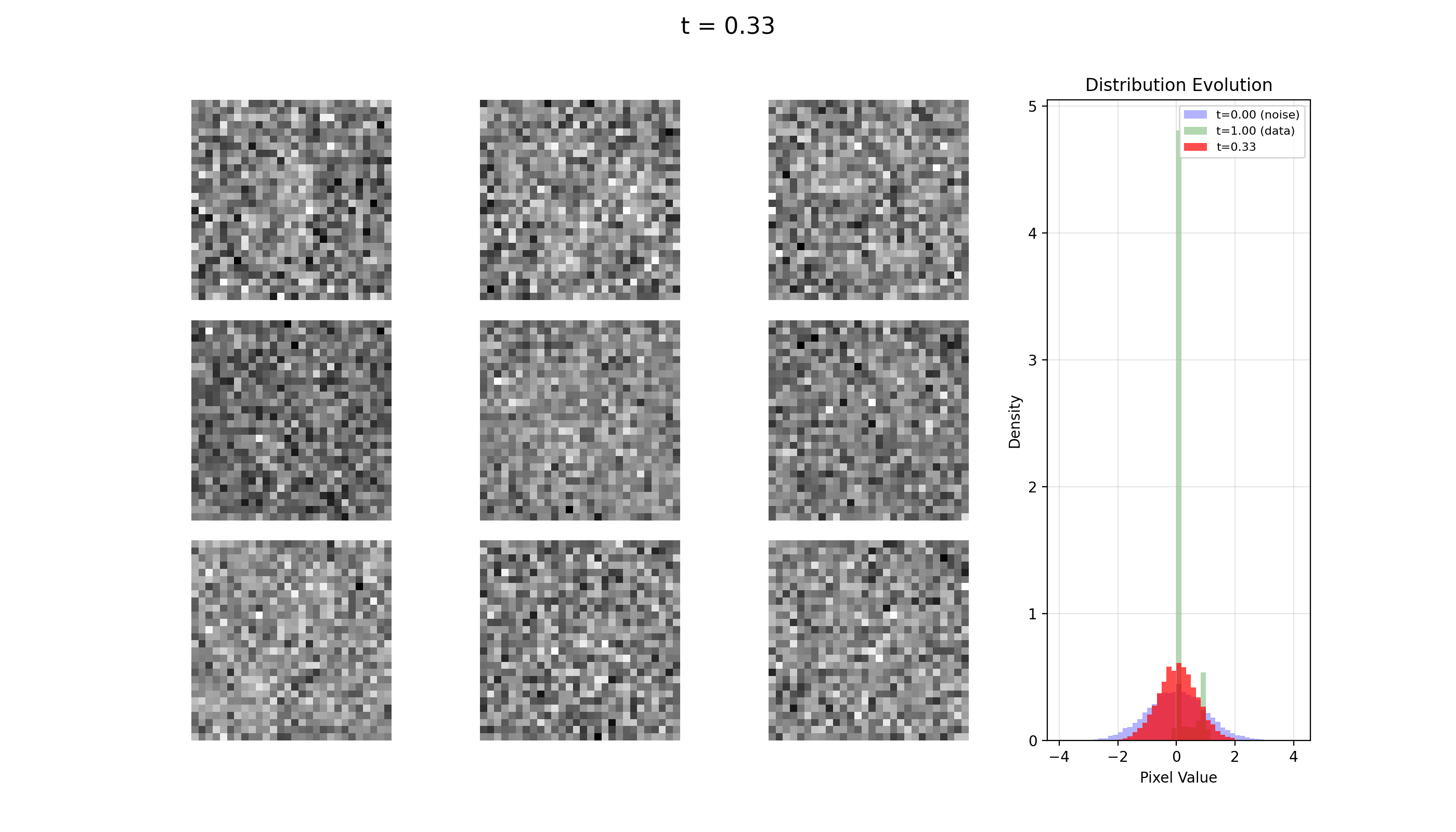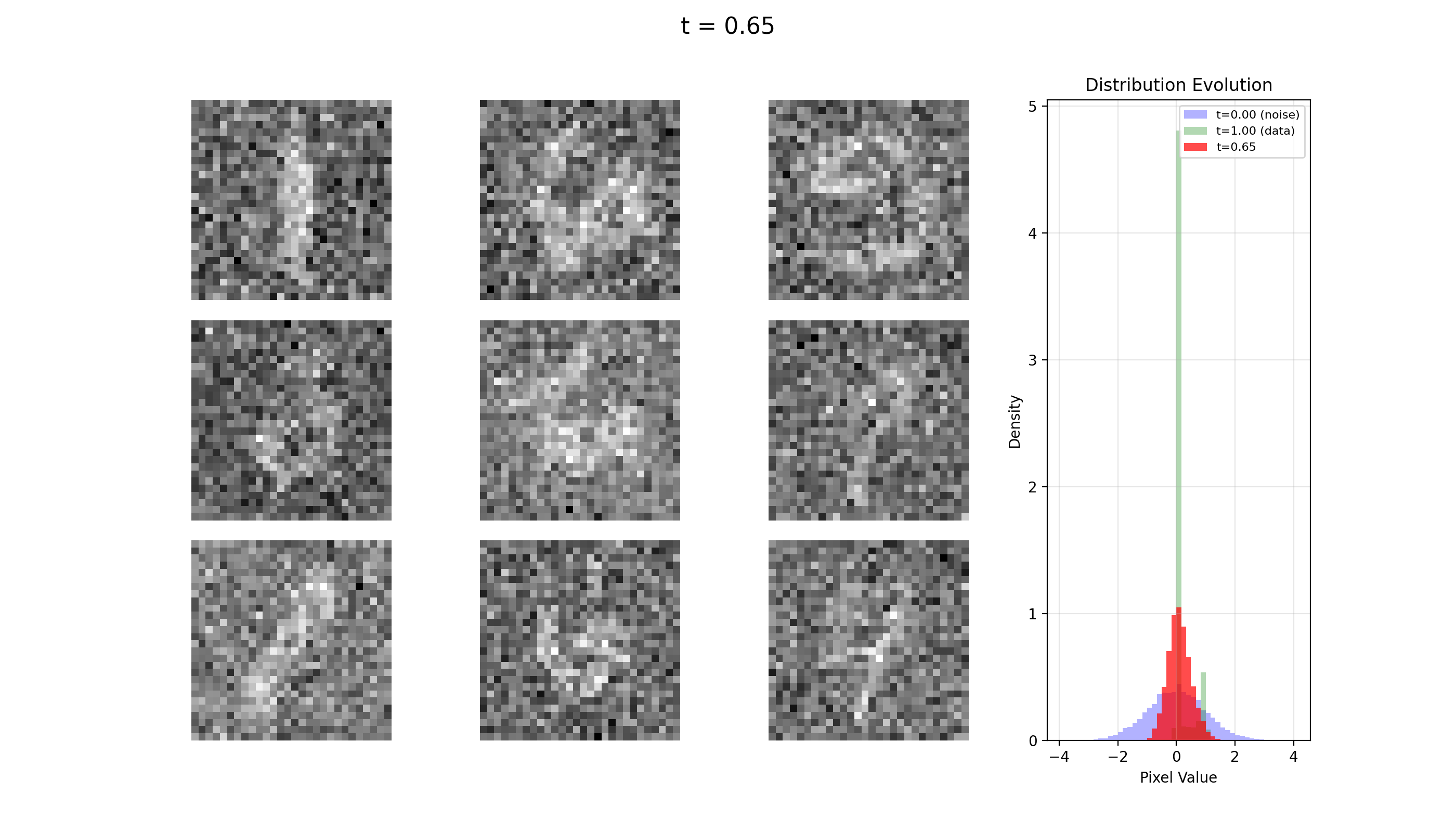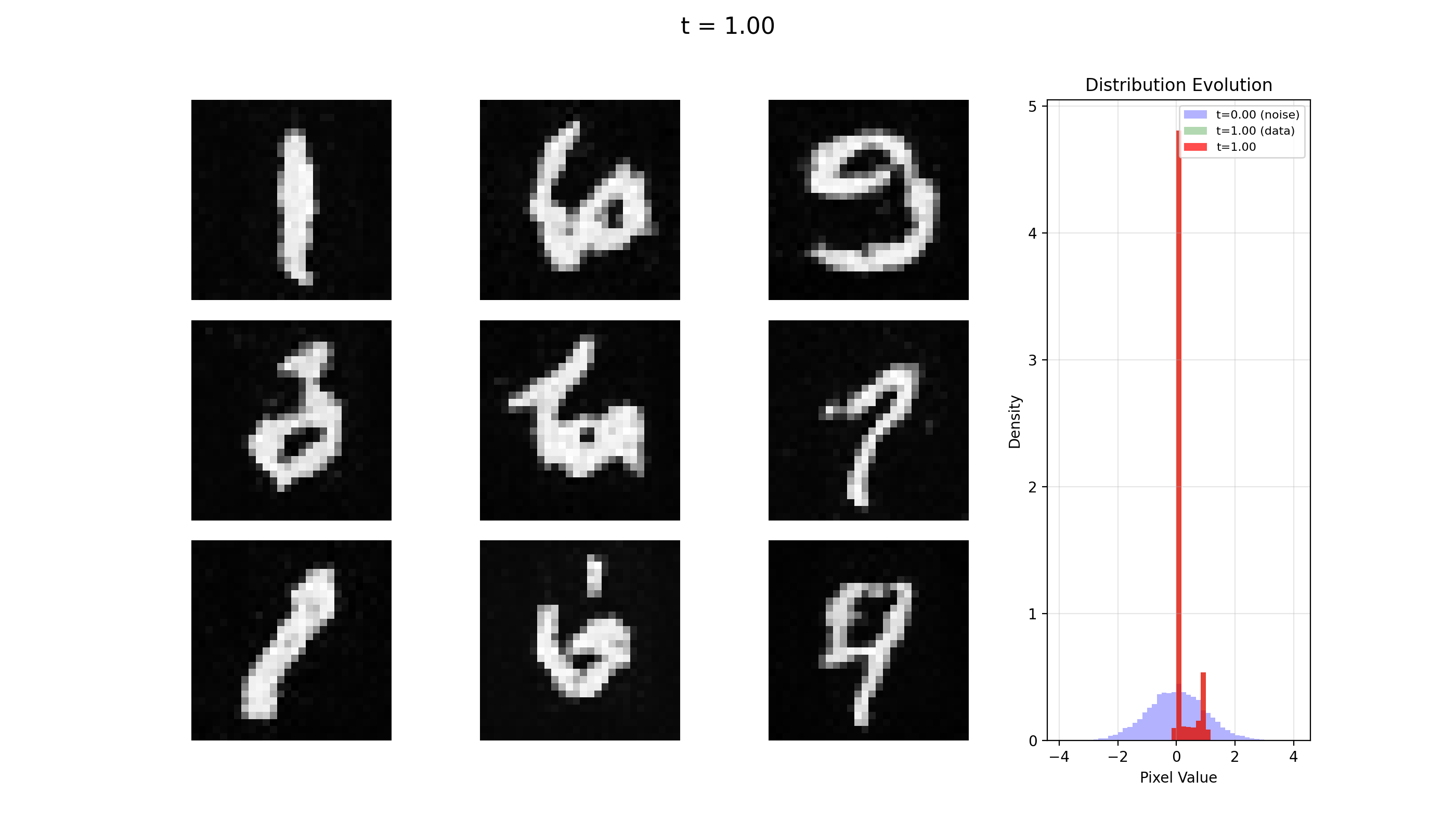
FashionMNIST

Lessons learned
tinygradpackage can be at least as powerful as PyTorch. It is lightweight, works on pretty much any hardware, and is very fast. However, it's a completely different paradigm with lazy execution. The model is built as a computation graph which you execute later as opposed to eager execution of PyTorch.- The training loop is where most things go wrong. Getting data sampling right took many iterations — naive approaches would collapse to sampling the same digits repeatedly. Shuffling and proper batching matter more than you'd expect.
- Start with a bigger architecture. For MNIST a small network is fine, even a medium sized MLP will do. For anything with more structure — FashionMNIST, CIFAR — a larger UNet from the start saves a lot of backtracking.
- Hydra configs helped manage the explosion of hyperparameters, but the config space grew faster than expected. It's useful scaffolding, though next time I'd be more disciplined about what actually needs to be configurable.
- MLflow was genuinely useful for tracking training and evaluation metrics across runs. When you're iterating over schedulers, solvers, and architectures, having a clean experiment log makes it much easier to compare what actually worked.
What's next
This has been a fun ongoing project that I genuinely enjoyed building. It taught me the inside of generative modeling via ODEs (my MSc and PhD were both focused on those!) and how to efficiently build on systems without large hardware available.
Contributions and feedback are welcome!
One ongoing difficulty is scaling this up to CIFAR-10, which is considerably harder. Here my main limitation is likely only hardware (can't fit a larger model) but I think it is doable with a better network and slightly more compute.
The code lives in the dedicated repo.
A few things I was trying to do but haven't had the time to push to completion yet:
- Improve image quality assessment via Frechet Inception Distance (FID). This is essentially a score from a model trained on image classification to assess how good our generated data is. FID is using Inception network but in my case I tried training a custom classifier from scratch which has not been successful so far.
- Explore better architectures for rank-3 tensors (images).
- Explore more flow matching-based algorithms. Some techniques like discrete flow matching are not explored in this package.